 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLARK: Learnability-Grounded Trajectory Selection for Efficient Reasoning Distillation
May 28, 2026We study trajectory selection for reasoning distillation, where teacher-generated reasoning trajectories are selectively used as supervision for a student model. Existing methods rely on heuristics such as trajectory quality or model confidence, but they often overlook whether a trajectory is learnable by the student. In this paper, we present LARK, a learnability-grounded method for reasoning trajectory selection. LARK selects trajectories that the student can learn efficiently while preserving the generalization of the full training distribution. At the core of LARK is a learnability factor $ρ$, which characterizes the rate at which the student's training loss decreases. To estimate this rate efficiently and maintain generalization, we introduce a learnability proxy and a $χ^2$-regularized selection policy that balances learnability and distributional coverage, both with strong theoretical guarantees on their estimation error. Empirically, LARK consistently outperforms data selection baselines across multiple base models and reasoning tasks. Diagnostic analyses show that the LARK score predicts downstream training utility and that LARK-selected trajectories induce faster supervised fine-tuning loss reduction. Our code is available at https://github.com/Tianrun-Yu/LARK.
Efficient Agentic Reasoning Through Self-Regulated Simulative Planning
May 21, 2026How should an agent decide when and how to plan? A dominant approach builds agents as reactive policies with adaptive computation (e.g., chain-of-thought), trained end-to-end expecting planning to emerge implicitly. Without control over the presence, structure, or horizon of planning, these systems dramatically increase reasoning length, yielding inefficient token use without reliable accuracy gains. We argue efficient agentic reasoning benefits from decomposing decision-making into three systems: simulative reasoning (System II) grounding deliberation in future-state prediction via a world model; self-regulation (System III) deciding when and how deeply to plan via a learned configurator; and reactive execution (System I) handling fine-grained action. Simulative reasoning provides unified planning across diverse tasks without per-domain engineering, while self-regulation ensures the planner is invoked only when needed. To test this, we develop SR$^2$AM (Self-Regulated Simulative Reasoning Agentic LLM), realizing both as distinct stages within an LLM's chain-of-thought, with the LLM as world model. We explore two instantiations: recording decisions from a prompted multi-module system (v0.1) and reconstructing structured plans from traces of pretrained reasoning LLMs (v1.0), trained via supervised then reinforcement learning (RL). Across math, science, tabular analysis, and web information seeking, v0.1-8B and v1.0-30B achieve Pass@1 competitive with 120-355B and 685B-1T parameter systems respectively, while v1.0-30B uses 25.8-95.3% fewer reasoning tokens than comparable agentic LLMs. RL increases average planning horizon by 22.8% while planning frequency grows only 2.0%, showing it learns to plan further ahead rather than more often. More broadly, learned self-regulation instantiates a principle we expect to extend beyond planning to how agents govern their own learning and adaptation.
Improving and Accelerating Offline RL in Large Discrete Action Spaces with Structured Policy Initialization
Jan 07, 2026Reinforcement learning in discrete combinatorial action spaces requires searching over exponentially many joint actions to simultaneously select multiple sub-actions that form coherent combinations. Existing approaches either simplify policy learning by assuming independence across sub-actions, which often yields incoherent or invalid actions, or attempt to learn action structure and control jointly, which is slow and unstable. We introduce Structured Policy Initialization (SPIN), a two-stage framework that first pre-trains an Action Structure Model (ASM) to capture the manifold of valid actions, then freezes this representation and trains lightweight policy heads for control. On challenging discrete DM Control benchmarks, SPIN improves average return by up to 39% over the state of the art while reducing time to convergence by up to 12.8$\times$.
K2-Think: A Parameter-Efficient Reasoning System
Sep 09, 2025K2-Think is a reasoning system that achieves state-of-the-art performance with a 32B parameter model, matching or surpassing much larger models like GPT-OSS 120B and DeepSeek v3.1. Built on the Qwen2.5 base model, our system shows that smaller models can compete at the highest levels by combining advanced post-training and test-time computation techniques. The approach is based on six key technical pillars: Long Chain-of-thought Supervised Finetuning, Reinforcement Learning with Verifiable Rewards (RLVR), Agentic planning prior to reasoning, Test-time Scaling, Speculative Decoding, and Inference-optimized Hardware, all using publicly available open-source datasets. K2-Think excels in mathematical reasoning, achieving state-of-the-art scores on public benchmarks for open-source models, while also performing strongly in other areas such as Code and Science. Our results confirm that a more parameter-efficient model like K2-Think 32B can compete with state-of-the-art systems through an integrated post-training recipe that includes long chain-of-thought training and strategic inference-time enhancements, making open-source reasoning systems more accessible and affordable. K2-Think is freely available at k2think.ai, offering best-in-class inference speeds of over 2,000 tokens per second per request via the Cerebras Wafer-Scale Engine.
Revisiting Reinforcement Learning for LLM Reasoning from A Cross-Domain Perspective
Jun 17, 2025



Reinforcement learning (RL) has emerged as a promising approach to improve large language model (LLM) reasoning, yet most open efforts focus narrowly on math and code, limiting our understanding of its broader applicability to general reasoning. A key challenge lies in the lack of reliable, scalable RL reward signals across diverse reasoning domains. We introduce Guru, a curated RL reasoning corpus of 92K verifiable examples spanning six reasoning domains--Math, Code, Science, Logic, Simulation, and Tabular--each built through domain-specific reward design, deduplication, and filtering to ensure reliability and effectiveness for RL training. Based on Guru, we systematically revisit established findings in RL for LLM reasoning and observe significant variation across domains. For example, while prior work suggests that RL primarily elicits existing knowledge from pretrained models, our results reveal a more nuanced pattern: domains frequently seen during pretraining (Math, Code, Science) easily benefit from cross-domain RL training, while domains with limited pretraining exposure (Logic, Simulation, and Tabular) require in-domain training to achieve meaningful performance gains, suggesting that RL is likely to facilitate genuine skill acquisition. Finally, we present Guru-7B and Guru-32B, two models that achieve state-of-the-art performance among open models RL-trained with publicly available data, outperforming best baselines by 7.9% and 6.7% on our 17-task evaluation suite across six reasoning domains. We also show that our models effectively improve the Pass@k performance of their base models, particularly on complex tasks less likely to appear in pretraining data. We release data, models, training and evaluation code to facilitate general-purpose reasoning at: https://github.com/LLM360/Reasoning360
SAINT: Attention-Based Modeling of Sub-Action Dependencies in Multi-Action Policies
May 17, 2025The combinatorial structure of many real-world action spaces leads to exponential growth in the number of possible actions, limiting the effectiveness of conventional reinforcement learning algorithms. Recent approaches for combinatorial action spaces impose factorized or sequential structures over sub-actions, failing to capture complex joint behavior. We introduce the Sub-Action Interaction Network using Transformers (SAINT), a novel policy architecture that represents multi-component actions as unordered sets and models their dependencies via self-attention conditioned on the global state. SAINT is permutation-invariant, sample-efficient, and compatible with standard policy optimization algorithms. In 15 distinct combinatorial environments across three task domains, including environments with nearly 17 million joint actions, SAINT consistently outperforms strong baselines.
Continuous Time Evidential Distributions for Irregular Time Series
Jul 25, 2023



Prevalent in many real-world settings such as healthcare, irregular time series are challenging to formulate predictions from. It is difficult to infer the value of a feature at any given time when observations are sporadic, as it could take on a range of values depending on when it was last observed. To characterize this uncertainty we present EDICT, a strategy that learns an evidential distribution over irregular time series in continuous time. This distribution enables well-calibrated and flexible inference of partially observed features at any time of interest, while expanding uncertainty temporally for sparse, irregular observations. We demonstrate that EDICT attains competitive performance on challenging time series classification tasks and enabling uncertainty-guided inference when encountering noisy data.
Risk Sensitive Dead-end Identification in Safety-Critical Offline Reinforcement Learning
Jan 13, 2023



In safety-critical decision-making scenarios being able to identify worst-case outcomes, or dead-ends is crucial in order to develop safe and reliable policies in practice. These situations are typically rife with uncertainty due to unknown or stochastic characteristics of the environment as well as limited offline training data. As a result, the value of a decision at any time point should be based on the distribution of its anticipated effects. We propose a framework to identify worst-case decision points, by explicitly estimating distributions of the expected return of a decision. These estimates enable earlier indication of dead-ends in a manner that is tunable based on the risk tolerance of the designed task. We demonstrate the utility of Distributional Dead-end Discovery (DistDeD) in a toy domain as well as when assessing the risk of severely ill patients in the intensive care unit reaching a point where death is unavoidable. We find that DistDeD significantly improves over prior discovery approaches, providing indications of the risk 10 hours earlier on average as well as increasing detection by 20%.
Medical Dead-ends and Learning to Identify High-risk States and Treatments
Oct 08, 2021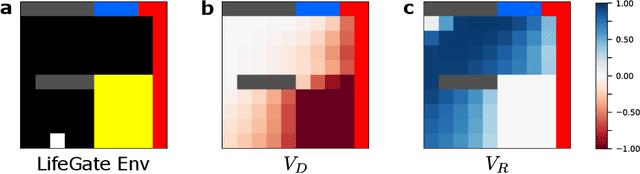
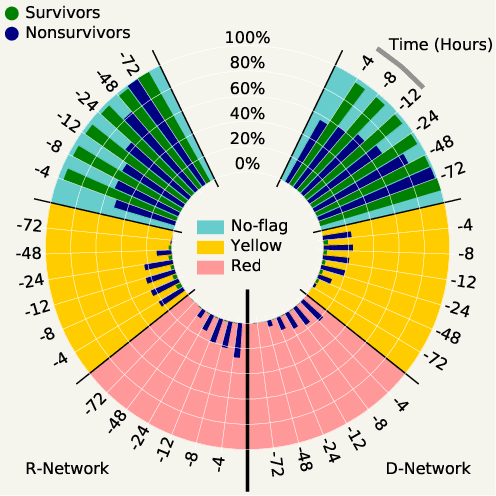
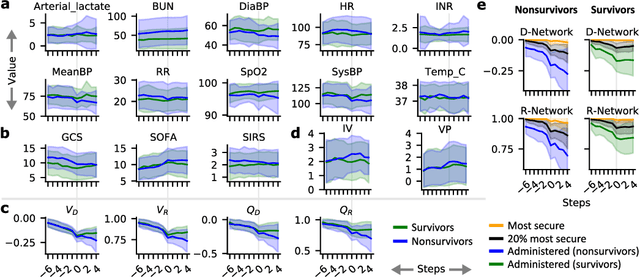
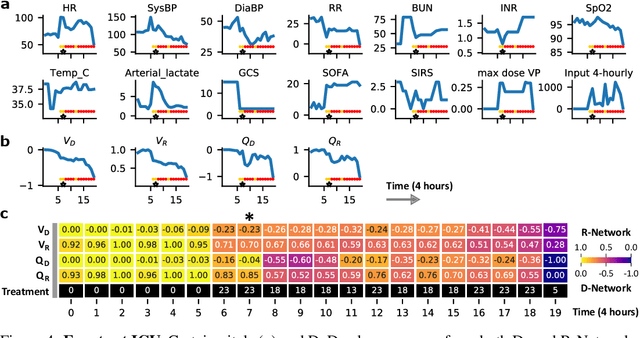
Machine learning has successfully framed many sequential decision making problems as either supervised prediction, or optimal decision-making policy identification via reinforcement learning. In data-constrained offline settings, both approaches may fail as they assume fully optimal behavior or rely on exploring alternatives that may not exist. We introduce an inherently different approach that identifies possible ``dead-ends'' of a state space. We focus on the condition of patients in the intensive care unit, where a ``medical dead-end'' indicates that a patient will expire, regardless of all potential future treatment sequences. We postulate ``treatment security'' as avoiding treatments with probability proportional to their chance of leading to dead-ends, present a formal proof, and frame discovery as an RL problem. We then train three independent deep neural models for automated state construction, dead-end discovery and confirmation. Our empirical results discover that dead-ends exist in real clinical data among septic patients, and further reveal gaps between secure treatments and those that were administered.
An Empirical Study of Representation Learning for Reinforcement Learning in Healthcare
Nov 23, 2020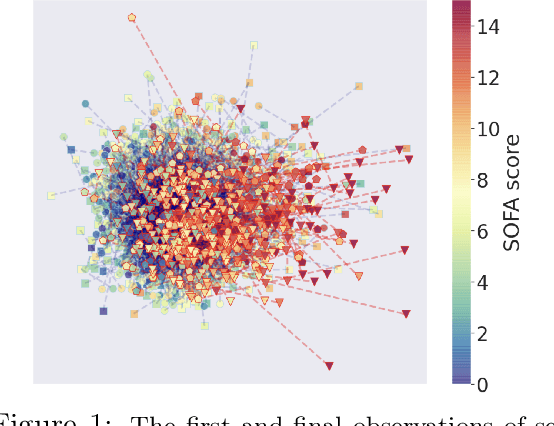
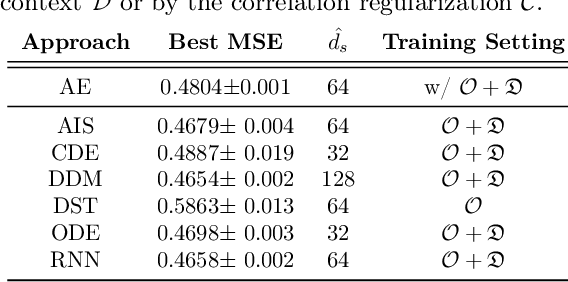
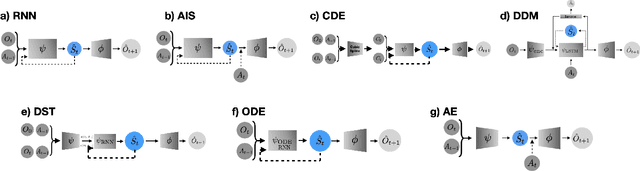
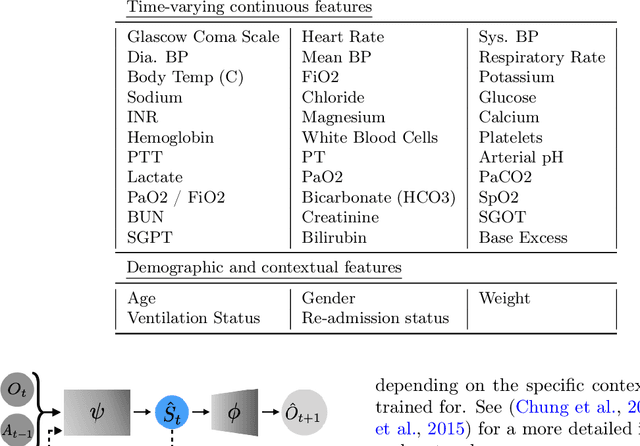
Reinforcement Learning (RL) has recently been applied to sequential estimation and prediction problems identifying and developing hypothetical treatment strategies for septic patients, with a particular focus on offline learning with observational data. In practice, successful RL relies on informative latent states derived from sequential observations to develop optimal treatment strategies. To date, how best to construct such states in a healthcare setting is an open question. In this paper, we perform an empirical study of several information encoding architectures using data from septic patients in the MIMIC-III dataset to form representations of a patient state. We evaluate the impact of representation dimension, correlations with established acuity scores, and the treatment policies derived from them. We find that sequentially formed state representations facilitate effective policy learning in batch settings, validating a more thoughtful approach to representation learning that remains faithful to the sequential and partial nature of healthcare data.